1
Implementaiton: Single Shot-MultiBox
Detector Using RESNET
Yannick Roberts, Robson Adem, and Yang Gao
Abstract
We implemented a method for effectively detecting as well as localizing objects in images using the approach,
named Single-Shot Detector. This method used a set of scalable boxes obtained from discretized output space of
bounding boxes. Then, a feed-forward convolutional network uses the scalable boxes to check the presence of each
category and give a confidence score. The network also performs a bounding box adjustment to produce a better
matching box for the object shape. The base of the network is designated for high quality image classification.
In addition, the auxiliary structure to the network is used to produce detections with the key features such as the
Multi-scale feature maps for detection, the Convolutional predictors for detection, and the Default boxes and aspect
ratios. SSD is straightforward to train, and it can easily be integrated to any applications. The main reason for this
is the fact that, unlike other methods, the SSD approach encapsulates all computation in a single network since it
does not use proposal generation and subsequent pixel or feature resampling stages. Using the RESNET network, we
implemented the SSD approach and obtained experimental results on the Dataset COCO2014 ( 82,000 Images; 82
Classes). We chose to use Resnet 18 becuase it maintiains the residuals from previous layers in the network. This
allows high level layers to directly access information from low levels. We premised this should lead to better results
than VGG.Following our experiments on 26 Epochs and close to 50 hours of training, we concluded that SSD has a
significant result in localization accuracy and a reasonable accuracy on detection.
I. INTRODUCTION
Object detection is the process localizing and detecting objects within an image. Classical image classification
entailed classifying a single object within an image. While state of the art classification accuracy could be achieved
with simple networks like AlexNet, the use case for such network remains limited to scenes with singular objects.
As the need for identifying objects within any arbitrary scene grew, research began devising new ways of detecting
and classifying objects. One of the landmark creations in such research entails the creation of RCNN; which was
first proposed in Selective Search for Object Recognition. To summarize, the network utilizes classical image feature
extraction techniques to determine specific regions of interest within a scene. From the these regions are passing
into a convolutional network where they are further classified or discarded. A bounding region and label is finally
determined and the results presented as the networks output. While this method was able to generate state of the art
results in detecting and classifying objects within a scene it failed to achieve the necessary performance to classify
scenes in real time; this is due to the feature extraction phase. Given the slow performance, another method was
introduced which increase the performance of RCNN network. This was called faster RCNN and relied on the
convolutional network to process image details. While performance was improved, both RCNN and Faster RCNN
2
relied on selective search to obtain potential region of interests. Selective search is an extremely slow algorithm
and significantly restricted either network performance.
To Remedy this situation, Wei Lui [?] et al developed a ground breaking network called SSD or Single Shot
MultiBox Detector which was designed to inline the entire region proposal network into the entire convolutions
network. As a result, the network is able to detect any arbitrary object with real time performance, significantly
bettering that of RCNN and other state of the art networks during that period.
II. PROBLEM STATEMENT
Given the potential performance gain and classification accuracy, we choose to implement of the single shot
multibox detector algorithm as described in the paper Single Shot-Multibox Detector [1] by Wei Liu Etal.
III. PROPOSED APPROACH
A. Single Shot Multibox Detector
The paper proposes that a pre-defined network be utilizes as the backbone for recognizing images; in the case
of the paper, VGG16 was proposed as the backbone network. The backbone network is further modified where
a set of 6 auxiliary convolution layers are added to the tale end of the final convolution layer of the VGG16
network. From here a set feature maps are extracted from the the final 2 layers of backbone network and after
each convolution layer of the auxiliary network. A total of 6 features maps are extracted. Each feature map is then
divided into regions determined by the scale of the feature map and a set of bounding boxes are defined for each
region. These bounding boxes, referred to as priors within the feature space, form the underlying foundation behind
the algorithm’s performance 1.
Fig. 1. SSD Priors defined in feature space.
A total of 8732 priors are established across the 6 extraced feature maps. Each prior is then pass through a
predictive head where their positions are regressed throughout the network with respect to the network’s cost
function. While processing the network criterion, the Jaccard Index is then calculated between the bounding box
ground truth. Priors with the greatest overlap are said to have a potential match and are passed to the localizing
and classification phase.
3
Fig. 2. Jaccard Index Used to calculate IoU measure.
B. Localization Loss
The localization loss is dependent on priors from the prior layer that had passed a specific threshold computed
by their Jaccard index. An L1 distance is then used as the localization loss function To regress the ground truth
locations across the network, and drive localization to convergence.As noted in equation 3, the localization loss is
the averaged smooth l1 loss between predicted offsets and matching priors filtered by their intersection over unions
with the ground truth.
Fig. 3. Localization loss relies on l1 difference between predicted boxes and associated priors.
C. Confidence Loss
In addition to the localization loss, the network also relies on the confidence loss to drive the classification of the
detected objects. Because the majority of selected priors does not coincide with a positive prediction, the network
focuses on priors that have the highest negative values. This method, called Hard Mining, ensures that the most
critical features within the selected priors are used to decipher what classes are present in said prior. As such, the
confidence loss follows equation 4, whereby the cross entropy loss between positive and hard negative elements
are calculated and averaged.
Fig. 4. Confidence loss relies on training the network on the most difficult features.
4
D. Total Loss
The total multibox loss is the sum of both the localization loss and classification loss. A coefficient λ is used to
weight the loss terms to optimize training for both classification and localization.
Ltotal = Lconf + λ ∗ Lloc
(1)
E. Network Modifications
In an attempt to improve the performance of the network as defined in the paper, [1], we proposed sought to
integrate a ResNet18 network as the backbone instead of the associated VGG16. Unlike VGG16, ResNet18 utilizes
residuals connections to improve information flow throughout the network. This has been proven to significantly
improve network performance [2], and should preserve small details which would also improve classification
performance. As such, a Resnet network pretrained on ImageNet was choosen as the backbone network for our
experiment. Because the output layers did not match that of the classical VGG16 network, we had modified the
initial and final layer parameters to allow ResNet to interface with the SSD’s auxiliary network.
Fig. 5. ResNet18 was used in place of VGG net.
IV. EXPERIMENTS
After implementing the network as described in Single Shot MultiBox Detector [1], we then trained our network
and compared the performance to what is declared in the paper. Table I presents the parameters choosen in training
the network. The network was trained for 26 epochs which correlated to approximately 48 hours on a single Nvidia
GTX 1070. The entire COCO2014 dataset was chosen for training and testing. This dataset consist of approximately
82,000 classes spanning 82 classes. Each image consisted of multi objects in a variety of scenes and poses.
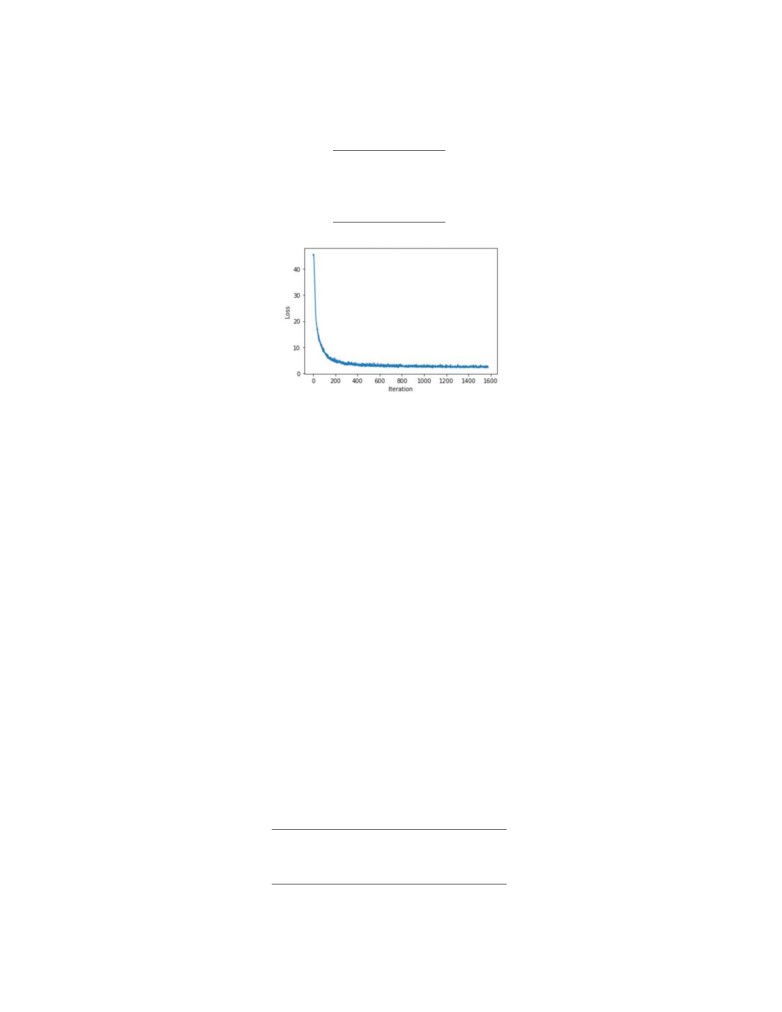
Given the above training details, the training loss for the network is described by 6. At the final moments of
training, the classification loss was reduced from 20 to 2.8 and the localization loss decreased from 11 to 0.7. While
we had to stop at such results, there was significant room to further imrpove the network just by increasing the
training time.
5
TABLE I
HYPER PARAMETERS USED DURING NETWORK TRAINING.
Param
SSD
Epochs
10
Batch Size
4
Learning Rate
0.001
Fig. 6. Total Loss vs Training Iterations
A. Results
Given the aforementioned training parameters, the network was able to localize and classify many object when
provided an image. Moreover the network was also able to identify obscured objects and provide a suitable bounding
box. While the localization and classification results did show potential, many images failed to correctly classify
various object within the scenes. Figure 7 showcases these results. As shown the dogs are correctly labeled but
the network incorrectly classified the cow as a horse. Similarly, the network was unable to localize the human in
against the sheeps.
When compared with the original SSD network and Fast RCNN, our implementation was not able to compare in
using Mean Average Precision. But it does achieve better results than Fast RCNN for performance. To summarize,
the network is able to present values at a rate of 10 fps, when ran on an Intel core i7. In contrast to Fast RCNN 7
fps our network is able to achieve better performance. We also expect, given more accurate localizing results given
more training time and a higher batch size.
TABLE II
COMPARISON RESULTS WITH SSD AND FAST RCNN.
Param SSD(Ours) SSD(official) Fast RCNN
mAP
10.2
74.8
73.2
FPS
10
59
7
6
Fig. 7. Confidence loss relies on training the network on the most difficult features.
V. RELATED WORK
One major state of the art methods for Object detection is RCNN. This method relies on a region proposal
network to define region of interest which is then passed into a CNN for classification. Now the Region Proposal
Networks usually rely on classical feature extraction algorithms to declare where regions of interests exists within
images. Determining these region of interests are usually computationally costly. While there are faster approaches
to implementing RCNN it remains relatively slow for real-time uses. Another method is called YOLO (You Only
Look Once). It works by first splitting the input image into a grid of cells, where each cell is responsible for
predicting a bounding box if the center of a bounding box falls within it. Each grid cell predicts a bounding box
involving the x, y coordinate and the width and height and the confidence. A class prediction is also based on each
cell. The single-shot detector for multiple categories when it is compared with the aforementioned related works it:
• does not re-sample pixels or features for bounding box hypotheses
• is faster than the previous state-of-the-art for single shot detectors
(YOLO). This is mainly because of
elimination of the bounding box proposals and the subsequent pixel or feature re-sampling stage.
• uses separate predictors (filters) for different aspect ratio detection, and applying these filters to multiple feature
maps from the later stages of a network in order to perform detection at multiple scales is significantly more
accurate, in fact as accurate as slower techniques that perform explicit region proposals and pooling (including
Faster R-CNN).
7
- With using multiple layers for prediction at different scales—we can achieve high-accuracy using relatively
low resolution input, further increasing detection speed.
Robust localization and classification could be achieved using predefined bounding boxes to capture features
within particular regions of an image. With enough training, classification and localization accuracy could be
significantly improved. Increasing the batch size would improve our network’s accuracy. Contrasted with VGG net,
Resnet implements skip connections between blocks. This allows the network better discern features of differing
categories by relying on direct information from prior layers.
VI. CONCLUSIONS
In conclusion, we were able to review multiple papers on image detection. In doing so we chose to implement
the Single Shot MultiBox Detector as described in paper [1]. We were then able to customize the network by
replacing the VGG16 network as described in the paper with ResNet18. To test our implementation we then trained
the network on the Coco dataset for 26 epochs and tested the network on a variety of images. The results, while
not perfect showcases relative accurate localization and classification and such performance could be improved with
further training. As such, our network was able to perform as expected.
REFERENCES
[1] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, and A. C. Berg, “Ssd: Single shot multibox detector,” Lecture Notes in
Computer Science, p. 21-37, 2016.
[2] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” 2015.
[3] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in 2016 IEEE Conference on Computer Vision and
Pattern Recognition (CVPR), pp. 770-778, 2016.